Automatische Texterkennung findet bei ORDA16 mit dem Software-Paket OCR4all statt. OCR4all kombiniert zur Projektlaufzeit (vergleichsweise) einfache Bedienbarkeit mit hervorragenden Erkennungsraten für gebrochene Schriftarten. Auf dieser Seite werden weitere Infos zum Procedere gesammelt.
Installation
Offizielle Seite mit Installationsanweisungen: Quickstart
Bitte den Installationsanweisungen für das entsprechende Betriebssystem folgen.
Eine alternative Anleitung für Windows:
Die Installation dauert, bitte ein bisschen Zeit mitbringen. Zunächst Docker auf dem Rechner installieren. Unter Windows das erste Häkchen im Installationsbildschirm („Use WSL 2…“) gesetzt lassen, den Desktop-Shortcut je nach Präferenz. Die Installation kann je nach System ein wenig dauern. Docker dient als Grundlage für die OCR4all-Installation und ist unbedingt notwendig.
Nach der Installation Docker Desktop öffnen, den Nutzerbedingungen zustimmen. Unter Umständen ist eine Nach-Installation einer neuen Version des sogenannten WSL Kernels notwendig. Dazu den Anweisungen auf dem Bildschirm folgen. Ich empfehle allerdings, stattdessen mit der Kommandokonsole die notwendigen Schritte vorzunehmen. Dazu mit Windows+R den Ausführen-Dialog öffnen und dort cmd.exe eintippen. Es öffnet sich die Konsole. In dieser eintippen: wsl --update. Es sollte nun zu lesen sein: „Installation: Windows-Subsystem für Linux“ mit einem Fortschrittsbalken darunter. Die Installation kann wenige Minuten dauern. Docker Desktop schließen und neu öffnen. Docker sendet automatisch statistische Daten an die Entwickler, was man in den Einstellungen (Zahnrad-Symbol oben rechts) allerdings manuell abstellen kann.
Wenn Docker korrekt startet, erscheint untenstehendes Bild. Das Starten von Docker kann jeweils eine Weile dauern. Beim ersten Öffnen wird außerdem ein Tutorial angeboten, das man aber problemlos überspringen kann, da keine für uns relevanten Informationen vermittelt werden.
Ich weiche nun von der offiziellen Installationsanleitung ab. In Docker oben mittig auf Search klicken und dort ocr4all eintippen. In den Suchergebnissen auf den Reiter Images wechseln, in dem sich etwa ein Dutzend Suchergebnisse finden sollten. Dort auf uniwuezpd/ocr4all klicken und Pull klicken. Nun lädt Docker OCR4all herunter. Das kann gerade auf schwächeren Systemen und je nach Internetverbindung bis zu 30 Minuten dauern. Danach empfiehlt es sich, Docker kurz neu zu starten.
Um OCR4all startbereit zu machen, muss noch einmal die Konsole (Windows+R -> cmd.exe) öffnen und folgenden Befehl eintippen oder hineinkopieren: docker run -p 1476:8080 --name ocr4all -v C:\Users\Public\ocr4all\data:/var/ocr4all/data -v C:\Users\Public\ocr4all\models:/var/ocr4all/models/custom -it uniwuezpd/ocr4all Bei erfolgreichem Eintippen rattert nun eine ganze Reihe von Statusmeldungen in der Konsole herunter, an deren Ende steht: Server startup in [xxxxx] milliseconds. Nun zurück zu Docker wechseln. In der Navigationsleiste links auf Containers klicken. Dort ist nun eine Zeile namens ocr4all, bei der als Status Running steht. Unter Actions auf das Stopp-Symbol klicken, das dann zu einem Start-Symbol wechselt. Die Konsole kann nun geschlossen werden.
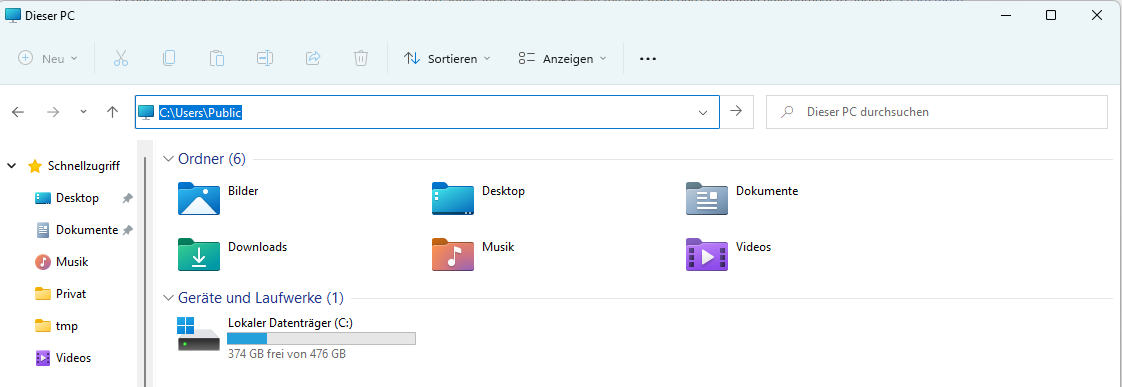
Jetzt überprüfen wir, ob OCR4all korrekt installiert und eingerichtet worden ist. Dazu öffnen wir den Windows-Dateiexplorer (Windows+E). In der Adressleiste (siehe Screenshot) eintippen: C:\Users\Public. Hier sollte sich nun ein Ordner ocr4all befinden. Es empfiehlt sich, einen Desktop-Shortcut anzulegen (Ordner mit rechter Maustaste anwählen und bei gedrückter rechter Maustaste auf den Desktop ziehen, dann im sich öffnenden Menü auf Verknüpfung anlegen gehen). In den Ordner hineingehen, dort in den Unterordner data steuern. Hier werden die OCR4all-Projekte zukünftig abgelegt. Wir legen zum Test einen neuen Ordner test an und in diesem Ordner einen weiteren Ordner namens input. Jetzt in Docker wechseln, dort bei dem Container ocr4all auf Start klicken. Jetzt im Internet-Browser (Firefox, Chrome, etc.) die Adresse localhost:1476/ocr4all eingeben. Dort öffnet sich nun die OCR4all Oberfläche. Wenn alles korrekt ist, zeigt sich unter Project das zuvor im Datei-Explorer angelegte test-Projekt.
Installation und Einrichtung sind nun abgeschlossen. Zukünftig ist OCR4all einfacher zu starten:
- Docker starten.
- Container ocr4all in Docker starten.
- Im Internet-Browser auf
localhost:1476/ocr4allgehen.
Zum Schließen:
- Container ocr4all in Docker schließen.
- Docker schließen.
Nutzung
Zur Nutzung gibt es eine offizielle Anleitung. Hier folgt zusätzlich eine eigene Auflistung der wichtigsten Punkte.
Jede Publikation wird in einem eigenen sogenannten Project behandelt. Projects werden manuell in der Ordnerstruktur von OCR4all angelegt, so wie oben für das test-Project beschrieben. OCR4all behandelt jeden Ordner in C:\Users\Public\ocr4all\data als neues Projekt. Als Projektname dient automatisch der Ordner-Name, es empfiehlt sich daher unbedingt sprechende Namen zu nehmen — hier z.B. die ORDA16-Nummerierung. Nachdem man sich bei einer Bibliothek den Scan als PDF heruntergeladen hat, legt man einen neuen Ordner im OCR4all-Verzeichnis an. In diesem Ordner wieder einen Ordner input anlegen, dort hinein die PDF-Datei kopieren.
Ruft man nun OCR4all über den Browser auf, lässt sich unter Project Overview -> Settings das gewünschte Projekt mit Load Project aufrufen. Liegt der Druck bisher nur als PDF vor, schlägt OCR4all vor, diese PDF-Datei in passende Bild-Dateien im PNG-Format umzuwandeln. Das ausführen, mit der Option leere Seiten zu behalten. Bei Dateien mit sehr vielen Seiten kann das lange dauern. Da wir nur die Paratexte benötigen, empfiehlt es sich hier, die PDF-Datei entsprechend zuzuschneiden, dass nur die relevanten Seiten noch enthalten sind. Das Original mit vollem Umfang muss dann aus dem Verzeichnis gelöscht werden, damit OCR4all nicht durcheinanderkommt. PDFs kann man bspw. mit PDFCreator oder PDFsam Basic zuschneiden.
Im Folgenden werden diese Schritte beschrieben:
- Preprocessing: Interne Verarbeitung der Original-Dateien.
- Segmentation: Automatisierte Erkennung der Layout-Struktur und Textregionen inklusive manueller Nachkorrektur.
- Recognition: Automatische Texterkennung mittels mitgelieferter Modelle.
- Post Correction: Manuelle Nachkorrektur der automatisch erkennten Texte.
- Result Generation: Export der korrigierten Texte.
Grundlegende Hinweise zur Bedienung: Die Seitenleiste lässt sich über das sogenannte Hamburger-Menü-Icon jederzeit einblenden. In der Hauptansicht lassen sich einzelne Menüpunkte durch Klicken auf die entsprechende Option ein- und ausblenden. Im folgenden Übersichtsfenster sieht man den Projekt-Fortschritt. Dort ist für jede Seite (0001 usw.) angezeigt, welche Verarbeitungsschritte bereits durchgeführt worden sind. Die Schritte Noise Removal und Line Segmentation werden übersprungen, alle anderen der Reihe nach durchgeführt. Auf das Training eigener Modell wird zunächst nicht eingegangen.


Preprocessing:

Das Preprocessing verarbeitet die Bild-Dateien so, dass OCR4all weiter damit arbeiten kann. In der rechten Leiste sind alle Seiten aufgeführt, die bearbeitet werden können. Standardmäßig sind alle Seiten zur weiteren Verarbeitung ausgewählt. Durch einen Klick auf den Haken neben Select all werden alle Häkchen entfernt. Möchte man nur einen bestimmten Bereich an Seiten bearbeiten, können diese manuell wieder angeklickt werden. Alternativ kann man die erste Seite auswählen und dann mit Shift+Linksklick auf die letzte Seite alle dazwischenliegenden Seiten markiert werden — ähnlich wie dies im Datei-Explorer funktioniert. Sind alle gewünschten Seiten ausgewählt, startet das Preprocessing durch einen Klick auf „Execute“. Unter Settings lassen sich bei jedem Schritt detaillierte Optionen einstellen. Im Allgemeinen ist dies jedoch nicht notwendig, so dass auch in den folgenden Arbeitsschritten alle Standard-Optionen beibehalten werden, sofern nicht explizit anders angegeben. Im Status-Fenster gibt OCR4all (mal mehr, mal weniger) hilfreichen Output zu aktuell laufenden Prozessen aus.
(Line) Segmentation:
Im nächsten Schritt wird automatisiert das Layout der eingespeisten Seiten analysiert. Dabei wird vor allem herausgefiltert, in welchen Bereichen der Seiten Text zu finden ist, der später erkannt werden soll. Diese Erkennung dient als Grundlage zur Line Segmentation, in der in den Textbereichen die einzelnen Zeilen des Textes markiert und getrennt werden. Für diese beiden Schritte stehen unterschiedliche Möglichkeiten zur Auswahl. Dabei ist die Segmentierung mit Kraken diejenige, die die besten Ergebnisse liefert. Kraken absolviert dabei beide Segmentierungsschritte in einem, während die anderen Verfahren eine separate Zeilensegmentierung erfordern.
Die gesamte Segmentierung funktioniert je nach Komplexität des zugrundeliegenden Layouts der Buchseiten unterschiedlich gut. Bei komplexeren Layout (z.B. Titelseiten, Bilder, Marginalien) ist oft eine manuelle Nachkorrektur notwendig, da die Textregionen und Zeilensegmentierung von Kraken dann keine fehlerfreien Ergebnisse liefert. Die Ergebnisse der Segmentierung lassen sich in Larex (Layout Analysis and Region Extraction) überprüfen. Larex ist ein in OCR4all integriertes Tool, das die Visualisierung und manuelle Nachbearbeitung der automatisierten Schritte von OCR4all ermöglicht. Geöffnet werden kann es über die Navigationsleiste und den Punkt LAREX. Eine Beschreibung von Larex erfolgt in einem eigenen Unterpunkt (am Ende des Textes?).
Fehlerhafte Erkennung erfolgt beispielsweise bei Bildern, in die teilweise Textabschnitte hineininterpretiert werden, oder bei Marginalien, die nicht als separate Textabschnitte erkannt werden (s. Abb. 7 & 8). Es ist elementar sämtliche Fehler in der Layout- und Zeilenerkennung bereits jetzt zu beheben, da sich etwaige Fehler in späteren Schritten nicht mehr korrigieren lassen, ohne das gesamte Procedere noch einmal zu durchlaufen.


Recognition:
Nun folgt der eigentliche Schritt zur Texterkennung. In diesem werden die Seiten zeilenweise durchgegangen und die enthaltenen Textbilder versucht in maschinenlesbaren Text zu überführen. Der Fehlerrate bei diesem Prozess hängt maßgeblich von der Qualität der Vorlagen und den verwendeten Drucktypen ab. Seit kurzer Zeit (Anfang 2022) sind die bereits vortrainierten mitgelieferten Modelle von OCR4all (genauer: Calamari) in der Lage, gebrochene Schriftarten ziemlich zuverlässig zu erkennen.
Für die Texterkennung wird der Schritt Recognition ausgewählt. Hier ist es ausnahmsweise notwendig, weitere Einstellungen vorzunehmen. Unter Settings (General) müssen die Modelle ausgewählt, mit denen die Erkennung durchgeführt werden soll. Diese unterscheiden sich je nach verwendeter Drucktype, sind im Falle von ORDA16 allerdings immer die selben 5 Modelle, die in ihrem Namen deep3_fraktur-hist enthalten. Nachdem die Modelle und die gewünschten Seiten ausgewählt worden sind, lässt sich der Prozess wie üblich durch Execute starten. Der nun durchlaufende Erkennungsprozess lässt sich im Status-Bereich live nachverfolgen, inklusive einer Schätzung der Sicherheit, mit der die Erkennung korrekt durchgeführt worden ist. Dieser Vorgang kann je nach Umfang eine Weile dauern. Bis zum Abschluss des Vorgangs ist keine weitere Eingabe seitens des/der Nuter:in mehr notwendig.
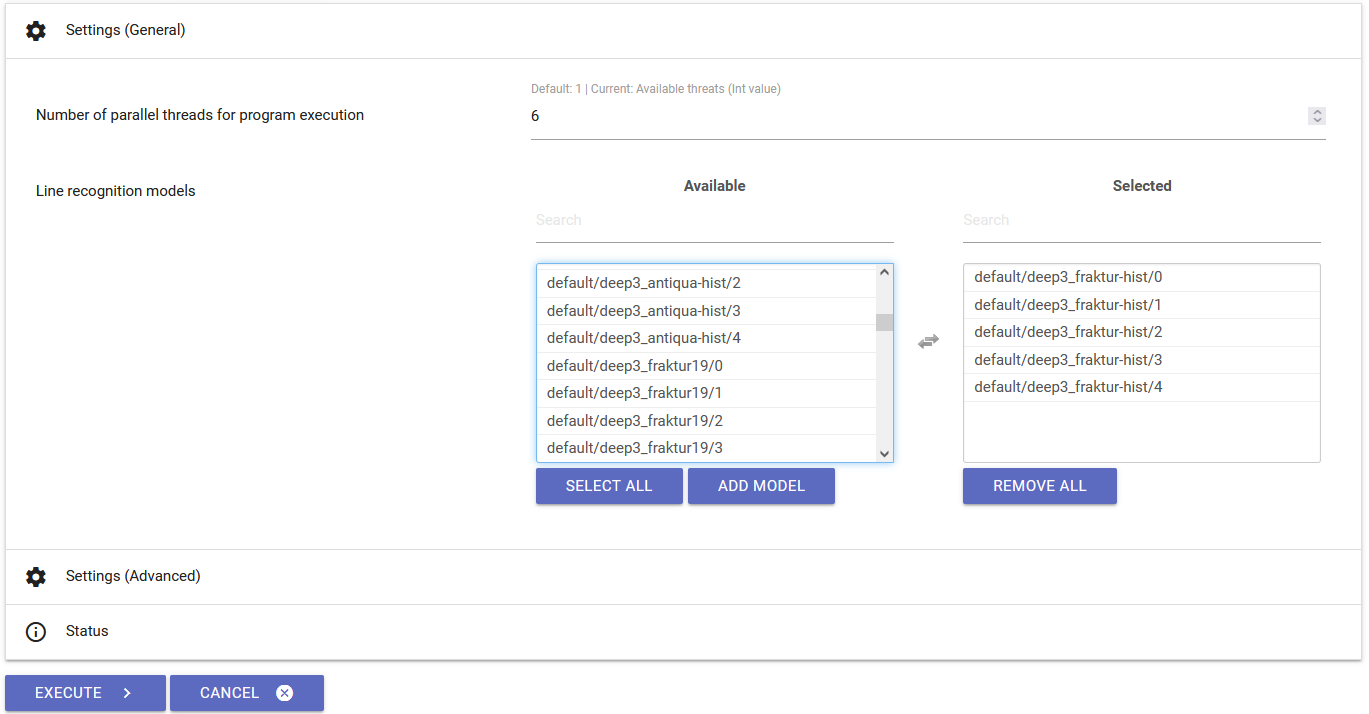
deep3_fraktur-hist ausgewählt. Im Status-Bereich lassen sich später die Ergebnisse des Erkennungsvorgangs live verfolgen.Post Correction
Die Fehlerraten mit den zuvor verwendeten Modellen liegt erfahrungsgemäß etwas unter 1 %. Das machte eine manuelle Nachkorrektur schnell abzuarbeiten. Die Nachkorrektur findet in Larex statt. In der aktuellen Version kann es hier leider manchmal dazu kommen, dass Larex nicht mehr oder fehlerhaft reagiert. In diesem Fall sollte Larex geschlossen und neu aufgerufen werden. Die exakten Umstände, unter denen das Fehlverhalten auftritt sind FF im Moment nicht klar.
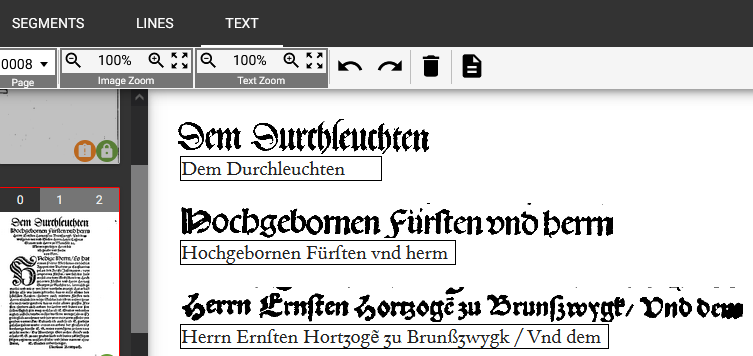
Nach dem Aufrufen von Larex in den Reiter TEXT wechseln. Dort wird zeilenweise zunächst das Bild, darunter dann der erkannte Text angezeigt (vgl. Abb. 10). Die Textzeilen können jetzt durchgegangen werden und Fehler in der Erkennung beseitigt werden. Dabei ist es wichtig, jede Zeile einmal auszuwählen, selbst wenn keine Fehler erkannt werden. So wird der Software mitgeteilt, dass die entsprechende Zeile als vollständig korrekt eingeordnet wird. Standardmäßig werden der korrigierte Text sowie der ursprüngliche samt Korrektur angezeigt (vgl. Abb. 11). Nachdem die gewünschten Zeilen einer Seite bearbeitet worden sind, muss das Ergebnis durch einen Klick auf SAVE RESULT in der rechten Steuerleiste gespeichert werden. Passiert das nicht, sind alle Änderungen verloren!

todo
Result Generation
Nachdem die Ergebnisse einer Nachkorrektur unterzogen worden sind und endgültig feststehen, können sie exportiert werden. In der aktuellen Version von OCR4all lassen sich die Ergebnisse als Text, Word-Dokument oder XML-Datei exportieren. Bis auf Weiteres ist noch nicht genau klar, wie die technischen Details der Implementation der Paratexte in die Webseite aussehen. Daher ist es empfehlenswert den Export in allen drei Formaten durchzuführen.
Die fertigen Exporte werden mitsamt aller weiteren im Verlauf der Bearbeitung angefallenen Dateien gesammelt auf Sciebo abgelegt. Dabei wird die Dateistruktur von OCR4all gespiegelt, d.h. einfaches Copy-Paste genügt. Für etwaige spätere Nachbearbeitungen und im Sinne der Nachhaltigkeit ist es unabdingbar, die Dateien nicht nur zentral für alle zugänglich, sondern auch in ihrem gesamten Umfang abzuspeichern. Eine dauerhafte (d.h. über Projektende hinaus) Lösung zur Speicherung wird von FF noch erarbeitet.
Larex
Larex (eigentlich LAREX für „Layout Analysis and Region EXtraction“) dient zur Klassifikation und Segmentation von gescannten Buchseiten. Es ist ein sehr umfangreiches Tool, dessen Möglichkeiten wir hier im Projekt nur zum Teil benötigen. In ORDA16 dient es vor allem zur manuellen Nachkorrektur, falls die automatisierte Segmentierung und Zeilenerkennung nicht fehlerfrei funktioniert hat. Eine offizielle Dokumentation findet sich hier.
In der Segmentierung werden automatisch diejenigen Bereiche des Bildes erkannt, in denen Text vorhanden ist. Manchmal kommt es dabei zu Fehlern, so dass Bereiche entweder fälschlicherweise als textenthaltend erkannt werden oder Textbereiche nicht oder nur teilweise als solche eingestuft werden. Beide Arten von Fehlern lassen sich durch Larex beheben.
Dazu öffnet man in Larex die entsprechende Seite. Zunächst wird die Korrektur der Segmentierung besprochen: Regionen, in denen bei der Segmentierung Text erkannt wurde, sind in lila dargestellt. Befindet sich Text außerhalb dieser Regionen, muss entweder eine neue Region angelegt werden oder eine bestehende entsprechend erweitert werden. Alle Arbeitsschritte müssen vor dem Schließen abgespeichert werden, damit sie nicht verloren gehen. Dazu existiert im rechten Menü der Punkt Save Result. Insbesondere bei größeren Änderungen empfiehlt es sich, immer mal wieder zu speichern, da Larex keine Art von automatischer Speicherfunktion besitzt. Vergisst man das Speichern sind alle ungespeicherten Änderungen dementsprechend unwiederbringlich verloren.

Eine neue Region lässt sich entweder über die Steuerleiste oder den Shortcut 3 anlegen (s. Abb. 13). So lässt sich mit der linken Maustaste ein Rechteck ziehen, das über dem nicht erkannten Text zu liegen kommt (s. Abb. 14). Beim Abschließen des Ziehens öffnet sich ein Kontext-Menü in dem die unterste Option TextRegion ausgewählt werden muss.

3 anlegen.
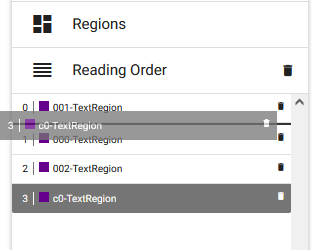
Die neue Region ist zunächst mit einer gestrichelten Linie umschlossen. OCR4all liest die Textregionen in einer bestimmten Reihenfolge. Neue Regionen müssen jeweils in diese neue Reihenfolge eingefügt werden. Die Lesereihenfolge lässt sich anzeigen, indem man im rechten Menü auf Reading Order klickt, und durch Zahlen bei 0 beginnend angezeigt. Bei der Erkennung wird die Seite entsprechend dieser Reihenfolge analysiert. Neue Regionen werden hinzugefügt, indem man die Regionen mit einem Mausklick auswählt — zu erkennen an der nun blauen Umrahmung und farbigen Füllung — und dann in der Steuerleiste (Abb. 13, rechts) im rechten Block Order auf die Option Add a region ... bzw. den Shortcut R klickt. Die neue Region ist nun in der Reading Order enthalten, allerdings als letzte zu lesende Region. Per Drag-and-Drop lässt sich nun die Region in dem Menüpunkt unterhalb von Reading Order an die korrekte Stelle verschieben.
Bereits existierende Regionen lassen sich erweitern oder verkleinern, indem man auf die entsprechende Region klickt, so dass ein blauer Rahmen mit kleinen Punkten an den Ecken erscheint. Diese Eckpunkte lassen sich mit dem Mauszeiger beliebig verschieben und die Form des Polygons entsprechend den Bedürfnissen anpassen. Neue Eckpunkte lassen sich erzeugen, wenn man mit der linken Maustaste auf eine blaue Linie klickt. Bestehende Punkte lassen sich Löschen, indem man sie mit einem Klick auswählt und dann mit der Entf-Taste löscht.
Für derart veränderte Seiten muss die Zeilenerkennung noch einmal separat durchgeführt werden. Es empfiehlt sich, das manuell durchzuführen. Kommt es auch sonst bei der Zeilenerkennung zu Fehlern, kann auf ähnliche Weise auch die Zeilenerkennung manipuliert werden. Dazu in Larex auf die Lines-Ansicht wechseln. Hier lassen sich nun analog zur Arbeit mit Regionen mit Zeilen verfahren. Es können neue Zeilen hinzugefügt werden, existierende angepasst oder verändert werden. Wichtig ist auch hier das Einfügen neuer Zeilen in die korrekte Reading Order und das Speichern aller Änderungen.
Todo: Ein paar Bilder